近日,2022年IEEE计算机与通信国际会议(IEEE International Conference on Computer and Communications 2022,以下简称IEEE INFOCOM 2022)录用通知发布,我院信息科学与技术学部江勇教授和王智副教授团队的两篇论文入选。IEEE INFOCOM是IEEE Communications Society主办的标志性旗舰会议,是计算机网络领域的顶尖国际会议,同时也是中国计算机学会推荐的A类国际学术会议,在国际上享有盛誉并具有广泛的学术影响力。INFOCOM 2022主会共收到论文投稿1129篇,最终接收225篇,录用率仅为19.9%。我院被录用的两篇论文主要涉及智能网络和强化学习领域的前沿研究,具体如下:
《Mousika:通过知识蒸馏在可编程交换机中实现通用网内智能》(Mousika: Enable General In-Network Intelligence in Programmable Switches by Knowledge Distillation),作者:计算机科学与技术专业2019级博士生谢国锐(一作)、计算机技术项目2020级硕士生董宇韬(学生二作)和段光林(学生三作),指导老师:江勇教授,本论文的研究工作与鹏城实验室李清研究员团队共同合作完成。

图1:谢国锐(左)、董宇韬(中)、段光林(右)
该论文的创新点为:训练了复杂且高精度的神经网络模型作为教师模型;在知识蒸馏算法中,将传统决策树改进为二进制决策树并作为学生模型,教师模型将自身积累的判断数据包类别的能力教授给学生模型;从二进制决策树中提取出分类规则,并编码成可编程交换机能使用的高效Ternary匹配流表规则项,下发到交换机执行数据包的分类任务。
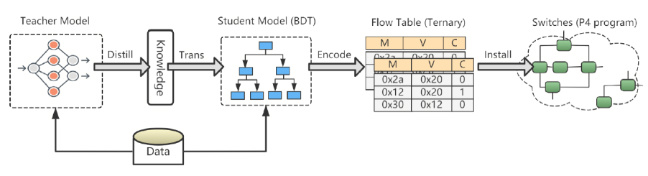
图2:Mousika框架
在数据包处理方面,可编程交换机不仅具有低延迟、高吞吐的优越性能特点,而且允许管理员通过一些简单的编程指令操纵数据包。然而,可编程交换机支持的编程指令还是比较弱的,比如仅支持整数的加减和位移操作,不支持浮点数运算。因此,一些高精度且复杂的智能模型如卷积神经网络、循环神经网络等几乎是不可能部署到可编程交换机中并对数据包进行分类的。而决策树作为一种基于规则的分类器,分类过程没有复杂的运算操作,十分适合在交换机上进行部署。因此,一方面为了利用可编程交换机强大的数据包处理能力,另一方面为了避免复杂模型的部署难题,我们设计了一套基于知识蒸馏算法的模型转换与部署方案(Mousika)——通过知识蒸馏算法把复杂模型转换成简单的决策树模型后再在交换机上进行部署。同时,为了优化决策树对交换机计算/内存限制的消耗,我们提出了使用二进制决策树模型来替代传统的决策树模型,极大减少了交换机资源使用。实验表明,Mousika的部署仅消耗2个交换机stage,TCAM占用率为1.7%,同时能承载高达100Gbps业务流的分类任务。
《低成本机器学习云服务联合推理:一种组合式强化学习方法》(Cost Effective MLaaS Federation: A Combinatorial Reinforcement Learning Approach),作者:计算机技术项目2020级硕士生解书照(一作)和2021级硕士生薛原(二作),指导老师:王智副教授。

图3:解书照(左)、薛原(右)
该论文的创新点为:首先,对主流云供应商的测量研究揭示了现有MLaaS产品之间的差异,以及MLaaS联合在提高分析性能方面的巨大潜力;其次,将MLaaS联合推理问题表述为一个组合式的供应商选择问题,并提出了一个基于组合强化学习的方法来最大化精度;最后,提出了有效的单词分组和预测结果聚合策略以统一来自不同供应商的标签,并汇总得到最终推理结果。该研究工作得到了国家自然科学基金(61872215)和深圳市科技计划(RCYX20200714114523079)的部分支持。
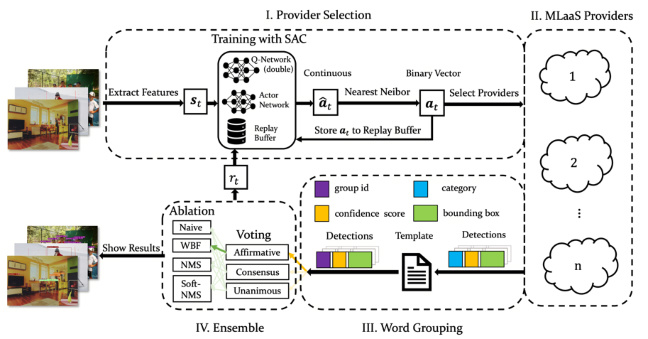
图4:低成本机器学习云服务联合推理框架
随着深度学习技术的发展,主流云供应商和小型机器学习服务供应商开始向公众提供机器学习云服务,这些服务也被称为“机器学习即服务”(Machine Learning as a Service,以下简称MLaaS)。根据对MLaaS的测量,我们发现对于同一任务,来自不同供应商的MLaaS由于专有的数据集、模型等特征而具有不同的性能,将不同的MLaaS联合起来能够进一步提高分析性能。然而,直接将来自不同MLaaS的结果聚合在一起,不仅会产生巨大的成本,而且还可能引入假阳性结果,从而导致次优的性能增益。在本文中,我们提出了Armol——根据输入自适应选择一个或多个MLaaS供应商以实现最佳分析性能的框架。首先,我们设计了一个单词分组算法,以统一不同供应商的输出标签。其次,我们提出了一种基于深度组合强化学习的方法,在最大限度地提高准确性的同时最小化成本。最后,使用精心选择的聚合策略将来自所选供应商的预测汇总在一起。现实的跟踪评估进一步表明,Armol能够在推理成本降低67%的情况下达到相同的准确率。
文:解书照、薛原、谢国锐、洪明春
图:解书照、薛原、谢国锐
编辑:黄萧嘉
