
Since 2018, pre-trained language models (PLMs) and the pre-training-fine-tuning approach have become the mainstream paradigm for natural language processing (NLP) tasks. This paradigm involves first pre-training large language models using massive amounts of unlabeled data through self-supervised learning to obtain a base model. Then, the model's parameters are fine-tuned using labeled data from downstream tasks through supervised learning to achieve task adaptation (Figure 1). Increasingly, experiments have shown that larger models not only perform better on known tasks but also demonstrate powerful generalization capabilities to complete more complex unknown tasks.
Large-scale pre-trained models such as GPT-3 and ChatGPT have emerged in recent years as representatives of this paradigm. However, the current practice of fine-tuning all parameters of large pre-trained models to achieve task adaptation consumes a significant amount of GPU computing resources and storage resources, severely limiting the application scenarios of these models. To address this challenge, parameter-efficient fine-tuning methods have gradually attracted attention. Compared with full-parameter fine-tuning, parameter-efficient fine-tuning methods freeze over 99% of the parameters of the pre-trained model and only optimize less than 1% of the model's size using a small amount of downstream task data as model plugins to achieve task adaptation. This method achieves performance comparable to full-parameter fine-tuning while significantly reducing the computation and storage costs of the fine-tuning process. A research team led by Hai-Tao Zheng from Tsinghua Shenzhen International Graduate School (Tsinghua SIGS) and Prof. Maosong Sun from the Department of Computer Science and Technology at Tsinghua University has delved into the mechanisms and characteristics of parameter-efficient fine-tuning methods for large-scale pre-trained language models.
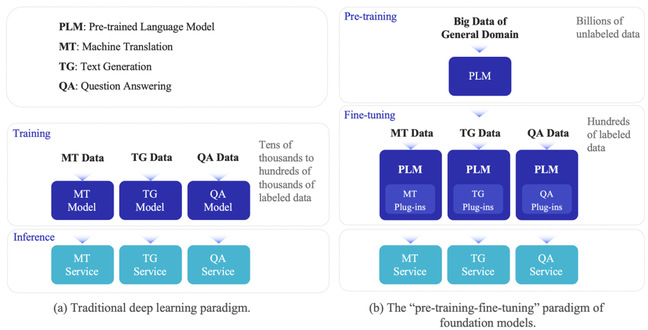
![]() Figure 1 The pre-training-fine-tuning paradigm and the traditional deep learning paradigm
Figure 1 The pre-training-fine-tuning paradigm and the traditional deep learning paradigm
The research team has proposed that the essence of parameter-efficient fine-tuning is adjusting the delta parameters.” They have named this type of method Delta Tuning and summarized the existing methods of Delta Tuning into three categories based on a unified analysis framework: Addition-based, Specification-based, and Reparameterization-based methods (Figure 2). To guide future model architecture and algorithm design, the research team further proposes a theoretical framework for Delta Tuning from two perspectives: optimization and optimal control, which provides a feasible approach for exploring and explaining the intrinsic mechanisms of Delta Tuning.

Figure 2 The framework of Delta Tuning from a unified perspective
The research team has conducted a comprehensive and detailed empirical study of mainstream Delta Tuning methods on over 100 natural language processing tasks. The study yielded several important conclusions. First, as the parameter scale of the base model increases, the performance of the model improves substantially, and the differences between different Delta Tuning methods decrease sharply (Figure 3). Only optimizing less than 0.008% of the model parameters is required to achieve promising adaptation. Second, different Delta Tuning methods can be combined in parallel or in series to achieve better performance, indicating that capabilities distributed in the model parameter space can be combined and generalized. Third, Delta Tuning methods have remarkable task-level transferability. The capabilities of completing specific tasks can be represented in a lightweight parameterized form that can be shared among different base models and users. The above research indicates that Delta Tuning is an important characteristic of foundation models. The conclusions drawn from this study deepen our understanding of the base model and provide essential support for its innovative research and application.

Figure 3 As the size of the foundation model increases, Delta Tuning methods can more effectively stimulate model performance
Since 2018, the research team has been committed to innovative research on large language models, and has been actively building the OpenBMB open-source community. The team aims to construct an efficient computing tool system for the entire process of large-scale pre-trained language models. Their work has accumulated over 4,000 stars on the largest open-source community platform GitHub and has received prestigious awards such as the Best System Demonstration Paper Award at ACL 2022, a renowned international conference in natural language processing. Based on the results of this research project, the team has developed and released an open-source toolkit called OpenDelta, which is an important part of the OpenBMB open-source community. This toolkit enables researchers and developers to efficiently and flexibly apply Delta Tuning methods to various pre-trained models. The research team believes that Delta Tuning technology will be an important paradigm for adapting base models to specific tasks, scenarios, and users, thereby more effectively unleashing the performance of large-scale pre-trained models such as ChatGPT.
This research was recently published under the title “Parameter-efficient fine-tuning of large-scale pre-trained language models” in the journal Nature Machine Intelligence. The project was jointly completed by researchers from the Tsinghua Department of Computer Science and Technology, including Maosong Sun, Juanzi Li, Jie Tang, Yang Liu, Jianfei Chen, and Zhiyuan Liu, and Hai-Tao Zheng from Tsinghua SIGS. Zhiyuan Liu, Hai-Tao Zheng, and Maosong Sun are the corresponding authors of this paper, and the first authors of the paper are Ning Ding and Yujia Qin. This research project was supported by the Ministry of Science and Technology's 2030 Science and Technology Innovation Project on New Generation Artificial Intelligence, the National Natural Science Foundation of China, Beijing Academy of Artificial Intelligence (BAAI), and the Tsinghua University Guo Qiang Instiute.
Link to full article:
https://www.nature.com/articles/s42256-023-00626-4
Written by Ning Ding
Edited by Alena Shish & Yuan Yang
